In addition, I know from other social media that folks are wondering about things that happen on their computers. Some issues are annoying, like spam in your email, others are scary, like activity that suggests you’ve been hacked, to just plain terrifying, like extortionary fraudulent emails.
Computer questions answered at the Ferndale Public Library
Until the pandemic lockdown began in March of 2020, my grandson, Christopher, and I held one hour public sessions at the Ferndale Public Library twice a month to answer computer questions. During these sessions we offered to try to help folks with any kind of computer problem. The problems ranged from annoying but minor email settings issues to high level discussions of XML data structuring for application interfaces. Both Christopher and I miss these sessions. We both like to help people, and, I’ll be frank, I think we both get pleasure out of showing off the knowledge of computing that we have accumulated.
Now that the grip of the pandemic is beginning to loosen a little, the possibility of reopening those computer questions sessions arises. My wife and I have each gotten our first vaccine injection and expect, following CDC guidelines, to begin mixing more in April.
Most likely not until Fall 2021
However, I don’t think it is realistic to expect sessions at least until fall of 2021. The vaccine statistics so far show the vaccines are effective at protecting people who are vaccinated, but there is not yet strong evidence that the vaccines stop the spread of the virus. The folks who study the course of the virus don’t know how many people have to be vaccinated to prevent unvaccinated people from continuing to get sick at high rates.
Having all that hurt condensed into a single year is difficult to comprehend.
The big question is when will vaccination prevent the virus from continuing to trouble our nation and the world? We have been troubled. More people are dead in one year of covid than from WWII, the Korean War, and Vietnam combined. I’m old enough to know that those wars were hard on us. Having all that hurt condensed into a single year is difficult to comprehend.
For me, stopping the spread of the virus is as important as protecting myself. Until the spread is stopped, our economy will only limp along and none of us will live the lives we want and deserve. Therefore, I plan to do everything I can to stop the spread, not just keep myself and loved ones alive. That’s selfishness, not altruism!
On top of that, hands-on help with computer problems in a small conference room is probably one of the more hazardous things a person can do in the presence a deadly and contagious airborne virus. So we won’t be restarting in person sessions at the library until covid cases are down. Way down.
A new Computer Questions page
But I don’t want to leave folks in the lurch.
But I don’t want to leave folks in the lurch. Therefore, I’ve opened a “Computer Questions” page on this site. Just enter your questions in the Reply section of the page. I’ll get back to you in a comment or write a post if I think enough people will be interested.
I really hope this can become as lively, helpful, and as much fun as our sessions at the Ferndale Library.
The SolarWinds hack is worrisome, but probably not for home computer users, although some caution is warranted. This week, the president of Microsoft, Brad Smith, declared the SolarWinds hack was the most sophisticated ever. Before we get to precautions, I’ll explain why the hack is such a big deal.
“I’ve been following this story closely as it has unrolled, and, frankly, it gets worse every day.”
Supply chain hacks
I’ve been following the story closely as it has unrolled, and, frankly, it gets worse every day. It is what the industry calls a “supply chain hack,” an indirect attack on an element in a target’s supply chain.
Instead of striking the target directly— for example, the inventory management system used by the U.S. Treasury Bullion Depository at Fort Knox— the hacker attacks the development facilities of an externally developed product that Treasury uses, an element in the Treasury digital supply chain.
The external product development lab is probably far less protected than Fort Knox. After gaining access, the hackers write in a nasty bit of malware, then wait for the Treasury to install the hacked product. When the product is installed, the hacker has an open door into Fort Knox and can begin dispatching shipments of gold bullion to an off-shore warehouse, Free On Board by the U.S. Army.
I doubt that Fort Knox is vulnerable in the way I’ve described, but a supply chain hack is a method for getting into a highly secure system without confronting the measures put in place by an institution that is guarded like Fort Knox.
SolarWinds hack
SolarWinds, an enterprise software company whose products I once competed with, was an outstanding choice for a supply chain attack. In the last few years, SolarWinds network management system has become popular among Fortune 500 enterprises and government agencies, including the U.S. Treasury.
Network management systems are used to monitor and control computing equipment on a network. Any organization with more than a few dozen computing devices is almost certain to have some sort of network management installed and that system is likely to touch every computer in the organization.
Personally, I have to think hard about this hack because I could have been a manager responsible for it. I was the technical leader in charge of products similar to SolarWinds. I made many decisions that affected the vulnerability of our products. Could my products have been infiltrated and subverted the same way SolarWinds was caught? I’ve been retired for almost ten years now, so be aware that anything I describe here is likely to have changed.
Nevertheless, I have to say yes. My projects could have been hacked. Quality assurance was a high priority. Some of our best customers were financial institutions and insurance companies who pushed us on security and we increased our security efforts with each release, but portions of our code were written before 2000 when security was not a high priority.
Also, hacking into development often has little connection with engineering. Dishonest, bribed or threatened employees, and rogue contractors all contribute to security vulnerability. Every large organization is bound to have a few bad eggs or weak links.
“In any large public corporation, the stock analysts often hold more sway than the security experts.”
And I must be honest. In any large public corporation, the stock analysts often hold more sway than the security experts. This is one reason I favor products that are certified secure with third party security audits. The best security audits include examination of both engineering and corporate governance, such as hiring procedures and controls on employee integrity. Stock analysts pay more attention to certification, especially certification by prestigious accounting and consulting firms, than opinions from security experts with qualifications a stock analyst probably knows nothing about.
Security at SolarWinds
“A key server is said to have been publicly accessible via a weak password “solarwinds123.”
Unfortunately, there are ample reports that SolarWinds security was poor. A key server is said to have been publicly accessible via a weak password “solarwinds123.” I have wandered computing convention show floors trying passwords like “oracle123” or “goibm” on unattended computers. In the early 2000s, those guesses quit working. Apparently, SolarWinds had some old timers setting passwords. Other poor security practices are said to have been common. Access to SolarWinds servers was also said to be on sale on the dark web.
Ironically, SolarWinds also develops and markets security auditing tools.
Origin of the SolarWinds hack
“I am reminded of the “mole” in author John le Carré’s 1974 spy novel Tinker Tailor Soldier Spy.”
Odds are great that it is a Russian government hack and more likely aimed at espionage and theft of plans and trade secrets than monetary gain. Which is good news for most home users, but the extent of the distribution of SolarWinds transported malware threatens both the U.S. government and economy. The U.S. may be dealing with this breach for years to come. I am reminded of the “mole” in author John le Carré’s 1974 spy novel Tinker Tailor Soldier Spy.
The bad news for home computer users is that criminal hackers may figure out ways to take advantage of the malware installed by the SolarWinds hack to gain access to software installed on home computers.
What to do?
Double down on basic computer security hygiene. I know that hygiene gets tedious, but criminals always go for the weakest victim. A few simple practices go a long way toward making a hack improbable. See my Six Rules for Online Security.
The SolarWinds hack underscores the importance of being careful when downloading and installing new software. Getting your software from established app stores, like the Microsoft Store, Google Play, or the Apple App Store is good practice because the stores vet the software they deliver. You still must be careful: malware has gotten through all of the stores. Software with tons of good reviews that has been downloaded frequently is safest. Never ever download anything from a site that does not show the https locked symbol on your browser. Check the reputation of your vendors and be sure you are on the real site, not a clever spoof.
Also, update your software regularly. Sign up for automatic updates whenever you can. The SolarWinds hack was spread by a software update, but that is not a reason to quit updating. The hack is also being neutralized by automatic updates and will be around far longer if folks neglect updates.
Run anti-malware regularly. The full extent and details of the hack are not yet known, but already anti-malware is cleaning up some of the mess.
For the last two decades, we’ve been in an era of free services: internet searches, social media, email, storage. Free, free, free. My parsimonious head spins thinking of all that free stuff.
Social and technical tectonic plates are moving. New continents are forming, old continents are breaking up. Driven by the pandemic and our tumultuous politics, we all sense that our world is changing. 2025 will not return to 2015. Free services will change. In this post, I explain that one reason free digital services have been possible is they are cheap to provide.
I’m tempted to bring up Robert Heinlein, the science fiction author, and his motto, TANSTAAFL (There Ain’t No Such Thing As A Free Lunch), as a principle behind dwindling free services, but his motto does not exactly apply.
Heinlein’s point was that free sandwiches at a saloon are not free lunches because customers pay for the sandwiches in the price of the drinks. This is not exactly the case with digital free lunches. Digital services can be free because they cost so little, they appear to be free. Yes, you pay for them, but you pay so little they may as well be free.
A sandwich sitting beside a glass of beer costs the tavern as much as a sandwich in a diner, but a service delivered digitally costs far less than a physical service. Digital services are free like dirt, which also appears to be free, but it looks free because it is abundant and easily obtained, not because we are surreptitiously charged for it.
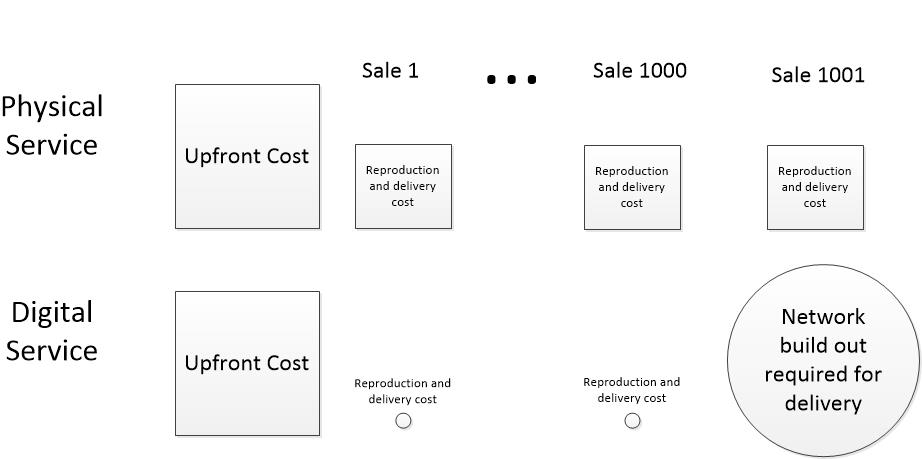
Each physical service sale has a fixed cost for reproduction and delivery. Digital services have almost no cost per sale for reproduction and delivery, until they have invest in expanded infrastructure.
Free open source software and digital services
One factor behind free digital services is the free software movement which began in the mid -1980s with the formation of the Free Software Foundation. The “free” in Free Software Foundation refers more to software that can be freely modified rather than to products freely given away, but most software under the Free Software Foundation and related organizations is available without charge. Much open source software is written by paid programmers, and is therefore paid for by someone, but not in ways that TANSTAAFL might predict.
The workhorse utilities of the internet are open source. Most internet traffic is Hyper Text Transmission Protocol (HTTP) packets transmitted and received by HTTP server software. The majority of this traffic is driven by open source Apache HTTP servers running on open source Linux operating systems. Anyone can get a free copy of Linux or Apache. Quite often, servers in data centers run only open source software. (Support for the software is not free, but that’s another story.)
So who pays for developing and updating these utilities? Some of the code is volunteer written, but a large share is developed on company time by programmers and administrators working for corporations like IBM, Microsoft, Google, Facebook, Amazon, and Cisco, coordinated by foundations supported by these same corporations. The list of contributors is long. Most large, and many small, computer companies contribute to open source software utilities.
Why? Because they have determined that their best interest is to develop these utilities through foundations like the Linux Foundation, The Apache Foundation, Eclipse Foundation, Free Software Foundation, and others, instead of building their own competing utilities.
By collaborating, they avoid wasting money when each company researches and writes similar code or places themselves in a vulnerable business position by using utilities built by present or potential competitors. It’s a little like the interstate highway system. Trucking companies don’t build their own highways, and, with the exception of Microsoft, computer companies don’t build their own operating systems.
Digital services are cheap
Digital services are cheap, cheaper than most people imagine. Free utilities contribute to the cheapness, but more because they contribute to the efficiency of service delivery. The companies that use the open source utilities the most pay for them in contributed code and expertise that amounts to millions of dollars per year, but they make it all back because the investment gives them an efficient standardized infrastructure which they use to build and deliver services that compete on user visible features that yield market advantages. They don’t have to compete on utilities that their customers only care about when they fail.
Value and cost of digital services are disconnected
We usually think that the cost of a service is in some way related to the value of the service. Digital services break that relationship.
Often, digital services deliver enormous value at minuscule cost, much lower cost than comparable physical services. Consider physical Encyclopedia Britannica versus digital Wikipedia, two products which offer similar value and functionality. A paper copy of Britannica could be obtained for about $1400 in 1998 ($2260 in 2021 dollars). Today, Wikipedia is a pay-what-you-want service, suggested contribution around $5 a month, but only a small percentage of Wikipedia users actually donate into project.
Therefore, the average cost for using Wikipedia is microscopic compared to a paper Britannica. You can argue that Encyclopedia Britannica has higher quality information than Wikipedia (although that point is disputable) but you have to admit that the Wikipedia service delivers a convenient and comparable service whose value is not at all proportional to its price.
Digital reproduction and distribution is cheap
The cost of digital services behaves differently than the cost of physical goods and services we are accustomed to. Compare a digital national news service to a physical national newspaper.
The up-front costs of acquiring, composing, and editing news reports are the same for both, but after a news item is ready for consumption, the cost differs enormously. A physical newspaper must be printed. Ink and paper must be bought. The printed items must be loaded on trucks, then transferred to local delivery, and hand carried to readers’ doorsteps. Often printed material has to be stored in warehouses waiting for delivery. The actual cost of physical manufacture and delivery varies widely based on scale, the delivery area, and operational efficiency, but there is a clear and substantial cost for each item delivered to a reader.
A digital news item is available on readers’ computing devices within milliseconds of the editor’s keystroke of approval. Even if the item is scheduled for later delivery, the process is entirely automatic from then on. No manpower costs, no materials cost, minuscule network delivery costs.
The reproduction and network delivery part of the cost of an instance of service is often too small to be worth the trouble to calculate.
My experience with network delivery of software is that the cost of reproducing and delivering a single instance of a product is so low, the finance people don’t want to bother to calculate it. They prefer to lump it into corporate overhead, which is spread across products and is the same whether one item or a million items are delivered. The cost is also the same whether the item is delivered across the hall or across the globe. Physical items are often sit in expensive rented warehouses after they are reproduced. Digital products are reproduced on demand and never stored in bulk.
Stepwise network costs
Network costs are usually stepwise, not linear, and not easily allocated to the number of customers served. Stepwise costs means that when the network infrastructure is built to deliver news items to 1000 simultaneous users, the cost stays the about same for one or 1000 users because much of the cost is a capital investment. Unused capacity costs about the same as used capacity— the capacity for the 1000th user must be paid for even though 1000th user will not sign on for months.
The 1001st user will cost a great deal, but after paying out to scale the system up to, say, 10,000 users, costs won’t rise much until the 10,001st user signs on, at which point another network investment is required. Typically, the cost increment for each step gets proportionally less as efficiencies of scale kick in.
After a level of infrastructure is implemented and paid for, increasing readership of digital news service does not increase costs until the next step is encountered. Consequently, the service can add readers for free without affecting adversely affecting profits or cash flow, although each free reader brings them closer to a doomsday when they have to invest to expand capacity.
Compare this to a physical newspaper. As volume increases, the cost per reader goes down as efficiency increases, but unlike a digital service, each and every new reader increases the overall cost of the service as the cost of manufacturing and distribution increases with each added reader. The rate of overall increase may go done as scale increases, but the increment is always there.
Combine the fundamental low cost of digital reproduction and distribution with the stepwise nature of digital infrastructure costs and digital service operators can offer free services much easily and more profitably than physical service providers.
The future
I predict enormous changes in free services in approaching months and years, but I don’t expect a TANSTAAFL day of reckoning because providing digital services is fundamentally much cheaper than physical services.
I have intentionally not discussed the ways in which service providers get revenues from their services, although I suspect most readers have thought about revenue as they read. The point here is that digital services are surprisingly cheap and their economic dynamics are not at all like that of physical goods and services.
As digital continents collide, I expect significant changes in free digital services, changes that will come mainly from the revenue side and our evolving attitudes toward privacy and fairness in commerce. These are a subjects for future posts.
For the last few days, I’ve been reading reports on the Trickbot takedown. U.S. Cyber Command and Microsoft have been hitting the large botnet, called Trickbot, that is controlled from eastern Europe, most likely Russia, and appears to have been maneuvering to interfere with the November 3rd U.S. election. The takedown steps apparently were planned strategically to give the botmasters little time to rebuild before the election. I sincerely hope the strategy succeeds. And I hope, and believe, that the Trickbot takedown is only the tip of an iceberg in a battle that is freezing out cyberattacks on our election.
We survived Y2K fears.
Trickbot
Trickbot, a botnet, is a multi-purpose covert criminal supercomputer cobbled together from thousands of hacked Windows computers. The botnet’s design offers few clues to hack victims that their devices are secret participants in criminal cyber attacks. The Trickbot crimes are mostly ransomware exploits for illegal profit. For some background on botnets see Home Network Setup: Smart Kitchen Crisis.
Y2K fears
The reports reminded me of Y2K fears, the year 2000 computer scare of 20 years ago. I hope those efforts are as successful as the Y2K remediation, which were so successful, Y2K was called a hoax by those who did not understand the computer industry.
Y2K and Bolivian basket weavers
I remember the Y2K affair well. It was no hoax. Everyone in the computing industry knew trouble was coming. Already in the early 1980s the issue was a hot topic among engineers. The problem went back to the early days of computing when data storage was expensive. It’s hard to believe today, but in the early days, the fastest and most reliable computer memory was hand-crafted by weavers from copper wire and tiny donut shaped ferrite magnets called cores. My meatware memory is not entirely reliable, but I remember hearing that Bolivian basket weavers were recruited to manufacture woven core memory. The computers on the Apollo moon mission were based on hard-wired ferrite cores.
Today, we talk about terabytes (trillions of bytes) but in those days, even a single K (1012 bytes) of memory cost thousands of dollars. I guess everyone today knows that a byte is eight bits, a sequence of eight 0s and 1s. Each donut magnet in core memory represented a single 0 or 1. The costing rule of thumb for handcrafted core memory was $1 a bit. At that price, a terabyte of memory would cost 8 trillion dollars, roughly the market price of 8 Amazons.
In the 1960s and 70s, programmers did not waste storage. They saved a few bytes by storing the year as two digits. 1913 was “13” and 1967 was “67.”
Most business programs used “binary coded decimal.” Storing the year as 2 digits instead of 4 was a savings of 8 bits: at near eight bucks a bit, close to $70 in 2020 dollars. Put another way, today, the price of those two 1970 bytes will buy 2 terabytes of flash memory, delivered to your door by Amazon. That flash memory would have cost 16 trillion dollars in 1970, filled several warehouses, and probably generated enough heat to warm New England for the winter.
Dates and the year 2000
Dates are used heavily in business computing, somewhat less in scientific computing. Accounting, scheduling, supply chain management all depend on date calculations. Today most of these calculations are handled in a few standard code libraries that are used over and over, but those libraries did not exist when the programs that ran the world’s business in 1999 were written. Each time a program needed a date calculation, a programmer wrote code.
Man, did they write code. Programmers delight in rolling their own, writing their own code. Coming up with an entirely original mundane date calculation will make a skilled coder’s heart sing. And there is joy in writing code that looks like it does one thing and does something quite different. These tastes decree that given an opportunity, coders will come up with many obscure and abstruse ways to calculate and analyze dates.
When I was hiring coders, I challenged candidates to describe an algorithm to determine the late fee on an invoice payment if 1% was to be added for each calendar month that had passed after the date the invoice was cut. If you think that description’s a little vague, you’re right. A hidden part of the challenge was for the coder to determine exactly what I had asked for. I don’t believe I ever got two identical solutions, and some would have behaved wildly if the calculations had crossed the Y2K boundary.
The industry took Y2K seriously
For good reason, in the late nineties, the industry got serious about the approaching crisis.
Y2K was a big deal. By 1995, I, along with many of my colleagues, had intentionally forgotten how to code in COBOL, the mainframe programming language of most 20th century business programs that were at the heart of Y2K issues. I won’t say that COBOL is a bad language, but few programmers cared for its wordy style. The scarcity of COBOL programmers elevated the language to a money skill in the last days of the century.
Y2K in my products
At that time, I was managing the development of a service desk product that I had designed several years before. I was coding almost exclusively in C++ on Unix and Windows, which uses an internal representation for dates and times that would not, in theory, have Y2K problems.
Nevertheless, management, who didn’t know that our product was theoretically immune to Y2K, declared my Fiscal Year 2000 bonus would depend on the absence of Y2K errors in our code. I smiled when I read the letter that described my bonus terms. Most years, fickle market conditions that I could not influence decided my bonus. This time, my bonus was in the bag due to a wise previous decision to build on a platform that sidestepped the central Y2K issue.
Still, I don’t mess around with my bonus. I started feeding Y2K use cases into our test plans, just to be sure.
I’m glad I did. Management, bless their bottom-line focused hearts, were right to worry about Y2K. It’s been a long time, but I estimate my team spotted and fixed a dozen significant Y2K defects that could have brought the product down or caused crippling errors.
Our defects were not COBOL style issues, but they stemmed from the two-digit year mindset that then pervaded business coding. For example, serial numbers often embed a two-digit year somewhere. A clever developer might use that fact and create a Y2K defect from it.
If those dozen defects had kicked in simultaneously on New Year’s Eve, service desks would have begun failing mid-Pacific in a pattern that would repeat itself as New Year’s Day followed the sun around the globe to Hawaii the next day. That was in a product running on platforms that were supposedly immune to Y2K errors. The devil in it was that a service desk would be used to manage the response to incidents that arose from other Y2K system crashes, compounding the chaos.
A real threat
People who are not responsible for building and maintaining computer systems probably don’t realize what happens when a raft of defects appear at the same time. Troubleshooting the origin of a malfunction caused by a single mistake can be difficult. With two mistakes, the problem becomes more complex and confusing. Each added source compounds the difficulty. At a certain point, the system seems to behave randomly, and you want to delete the whole thing and start over.
In the bad old days, we often saw large software projects break in dozens of places at once when we fired up them up for the first time. We used to call it “big bang” testing. Since writing code is more fun than testing code, many developers embraced the methodology and put off testing. But untested code is buggy code. Those big bangs were intractable messes of defects that could take weeks and months to untangle. We soon learned to test small units of code early and often, before mild-mannered projects became monsters.
As testing proceeded in development labs, engineers began to recognize that Y2K threatened to be a mass conflagration like those big bang debacles. Worse. Y2K bugs were everywhere. Their corruption extended to hundreds of systems. Unremediated Y2K threatened software mayhem like I have never seen and hope to never to see.
The reaction
Some engineers seized the limelight by overreacting. Doomsday prophets got wind of what was happening in development labs all over the globe. They went to the media with predictions of the imminent collapse of financial systems, communications, and power grids, which threatened to halt the economy and provoke the mother of all economic disasters. ATMs and traffic lights were about to go out of control. The preppers stockpiled guns, freeze-dried chili, and toilet paper enough to isolate for months.
Y2K at CA Technologies
I checked in to the CA Technologies (then Computer Associates) development lab in Kirkland on the Seattle east side early in the morning of December 31, 1999. As the senior technology manager in Seattle, I had orders to gather a team of developers and support people to man an emergency response hotline. The idea was that any Computer Associates customer with any Y2K problem could call the hotline and get expert help. Most engineers thought this was a transparent marketing ploy to take advantage of fears that had been whipped to a frenzy by the doomsday crowd.
Highly publicized orders were issued that development teams were on the hook until the last Y2K customer issue was resolved. The company supplied special Y2K tee-shirts. A buffet of sandwiches and periodic deliveries of pizza and other snacks were set up in a large conference room we called the board room. A closed-circuit television feed from headquarters in New York was beamed onto a then-rare wall-sized flat video screen. Rumor said champagne was scheduled to arrive at midnight.
The big letdown
I honestly can’t remember if the bubbly ever appeared. Late in the afternoon, I told all my crew they could leave if they wanted. I had to stay until midnight, but there was no reason to spoil their New Year’s celebration.
Why? On the Pacific Coast, we were among the last time zones to flip to 2000. In the morning, a customer called to headquarters in New York with a minor problem in Australia. It was fixed in minutes–mostly a user misunderstanding as I recall. The Kirkland team was not called on once. Typical developers, the crew loaded up on free sandwiches and pizza, took the loot to their cubicles and silently worked on code. A few salespeople wandered in to check on the action; there was none.
After all the buildup, why the big meh? Because humans aren’t stupid. The industry responded to the danger with testing and fixing. I’ve seen and believe estimates that upwards of $200 billion were spent on Y2K remediation in the 1990s. That was money well-spent. Consequently, Y2K came and went with barely a ripple.
The Y2K hoax
I take it back about humans not being stupid. We immediately began to hear about the Y2K hoax, a conspiracy and scare tactic for whatever purpose the speaker or writer found convenient. I’m sure the loudest criers of hoax were the same loudmouths who screamed computer Armageddon. I’d like to roll back the calendar and give the world a taste of what would have happened if Y2K had been ignored.
Actually, I wish Y2K had been ignored outside the industry and the people who understood the problem were allowed to quietly fix it without all the noise.
But that wouldn’t be right either. We were not heroes. The cost of the Y2K remediation was the price of poor judgement. Acting as if it did not occur would only encourage future bad choices. The remediation was nothing to be proud of. The industry should be called to account.
Nonetheless, in my dark moments, I have no patience for people who broadcast opinions but don’t carry water, put out fires, and make things work. Not everyone was fortunate enough to be in on the action of Y2K, not everyone has the training and experience to know what it takes to keep our computer-dependent society viable.
Y2K and the general election
Which brings us back to the Trickbot takedown. November 3rd 2020 has begun to smell to me like the approach of January 1st 2000. I see real danger and a dead serious response. I’m not an active member of the cybersecurity community, but I keep up. I have no doubt that criminals, extremists from every corner of the political spectrum, and foreign nation-states are planning cyber attacks to extort payments from election agencies, stop people from voting, slow vote tallies, and question results.
Election tampering hoax
But I also see the seriousness and competence of the efforts to prevent and neutralize these bad actors. Some signs point to success. Already, two weeks before the election, 29 million voters have voted, almost five times the number that had voted at this point in 2016. I’m sure election day will be tough, but I will not be the least surprised to hear another big meh on November 4, followed by cries of “election interference hoax!” from every direction, but from my vantage now, it’s clear it is no hoax.